
ЦЕЛЬ ПРОЕКТА
Создать собственную генеративную модель на базе Stable Diffusion, обученную на авторских фотоработах, и исследовать возможность переноса индивидуального визуального стиля в нейросреду.

ИСХОДНЫЕ ИЗОБРАЖЕНИЕ

В качестве исходного материала я использовала серию фотографий, снятых в Гонконге для новой коллекции бренда Asia st71. Этот город был выбран не случайно: его визуальная среда — плотная застройка, неоновые вывески, поток людей и культурные маркеры — формирует узнаваемую атмосферу, которая напрямую влияет на характер изображений.

РЕЗУЛЬТАТЫ ИЗОБРАЖЕНИЙ


фото+фрагмент кода к нему


фото+фрагмент кода к нему


фото+фрагмент кода к нему


фото+фрагмент кода к нему


фото+фрагмент кода к нему


фото+фрагмент кода к нему


фото+фрагмент кода к нему
ПРИНЦИП РАБОТЫ КОДА
Проверяем GPU и Устанавливаем необходимые библиотеки для дальнейшей работы (для описания изображения и обучения модели ии).
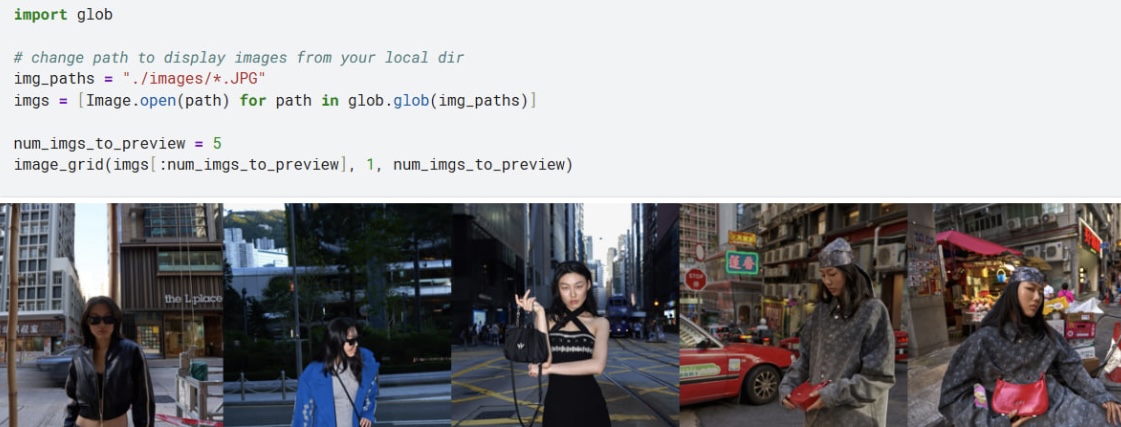
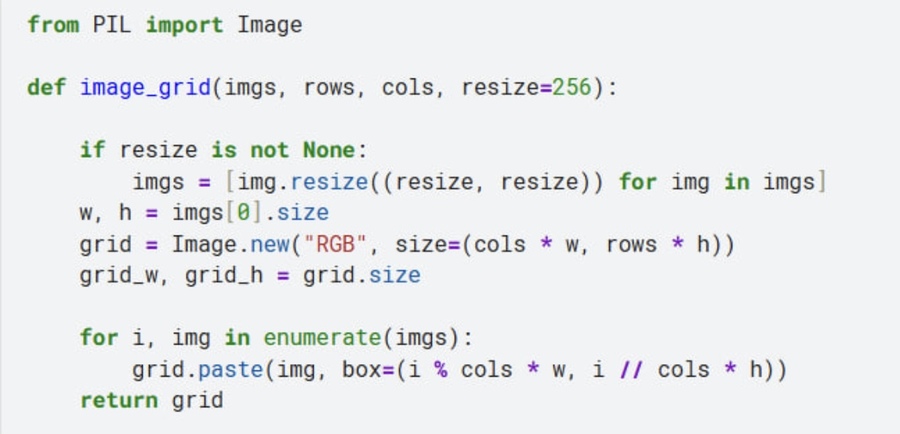
Выводим наш датасет с фотографиями с помощью заготовленной функции. В общем числе у нас получилось 39 фотографий для создания модели. Это оказалось мало и далее мы увидим почему.
Основное написание по которому будем генерировать фотографии «make photo in Karina style».
Такой вывод получился по сгенерированным подписям.
Далее у нас идет создание параметров для нашей модели. Выбираем разрешение 512, количество шагов обучения ставим 500, чекпоинт 250. Это сократит время обучения нашей модели.
Как итог, мы видим, что фотографии оказались не совсем идеальные: неровные черты частей тела, не всегда удачная генерация лиц, рук и особенно пальцев (это то, что очень долго не получалось делать у ИИ). Но наша модель смогла обучиться тому, что определила позы модели, общие черты лица и тела, фон. Но на некоторых фотографиях был намеренно размытый фон для передачи динамики большого города. Естественно, это повлекло за собой то, что наша модель иногда не могла точно его разобрать. Можно увеличить датасет с фотографиями до 500-1000 штук, увеличить шаги при обучении (от 1500 шагов). Это увеличит время создания модели, но в этом случае она лучше рассмотрит фото для генераций.



