
Проект показывает структуру MRI-датасета для распознавания стадий деменции. Основная идея: сделать видимым не только медицинский сюжет, но и устройство данных, какие классы представлены хорошо, какие почти исчезают из выборки, и почему это важно для обучения модели
В основе инфографики лежит MRI-датасет с изображениями мозга, разделенными на четыре класса: отсутствие деменции, очень легкая деменция, легкая деменция и умеренная деменция, поэтому главный фокус проекта — не описание симптомов, а визуальный анализ того, как болезнь представлена внутри набора данных. Эта тема выбрана потому, что болезнь Альцгеймера связана с одной из самых важных проблем современной медицины: ранним выявлением нейродегенеративных изменений. Чем раньше замечены признаки нарушения, тем больше возможностей для наблюдения, поддержки пациента и планирования лечения. Цель инфографики — объяснить, как устроен набор медицинских изображений для распознавания стадий деменции и какие выводы можно сделать еще до обучения алгоритма.
Польза проекта в том, что он переводит сложный медицинско-технологический материал на понятный визуальный язык. Для обычного зрителя инфографика объясняет, что искусственный интеллект в медицине зависит от качества данных

Описание процесса создания
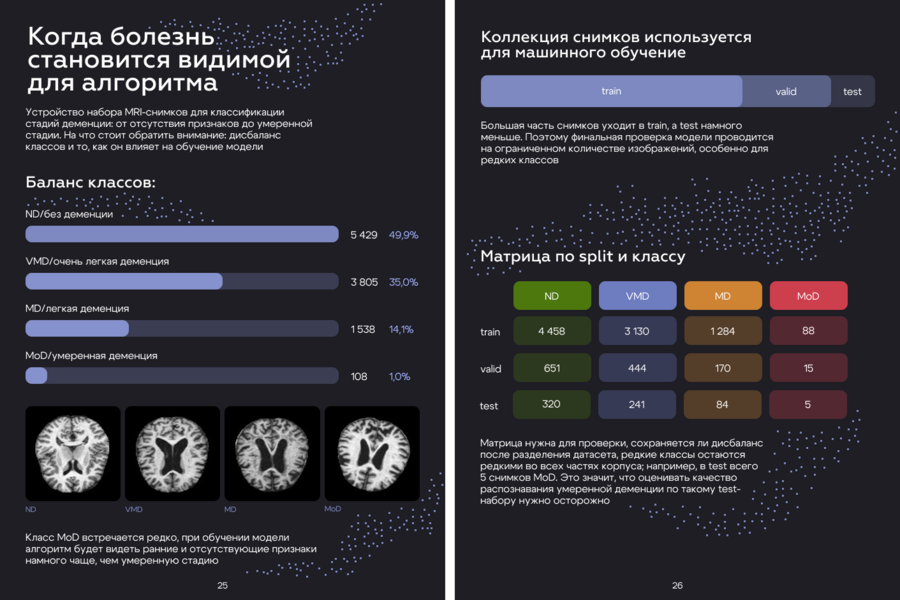
Сначала я изучила датасет и посмотрела, из каких материалов он состоит, в нем собраны MRI-снимки мозга, разделенные на группы для обучения и проверки модели. На этом этапе было важно понять, сколько всего изображений есть в наборе, какие стадии деменции в нем представлены и насколько равномерно распределены данные. После этого я посчитала, сколько снимков относится к каждой категории: без деменции, очень легкая деменция, легкая деменция и умеренная деменция. Эти подсчеты я сверила с таблицами из датасета, чтобы убедиться, что данные совпадают, так появилась основа для будущих схем: общее количество снимков, соотношение стадий и распределение изображений между частями датасета. На основе обработанных данных были выбраны четыре визуальные схемы. Первая: диаграмма баланса классов, потому что она сразу показывает масштаб различий между группами, вторая: схема train/valid/test, объясняющая, как датасет используется в машинном обучении, третья: визуальная шкала стадий с MRI-миниатюрами, чтобы зритель видел связь между классами и реальными изображениями, четвертая: матрица, которая показывает, сохраняется ли дисбаланс внутри каждой части датасета.
Использованные инструменты
В проекте использовался Codex для анализа и производства, он помог разобрать структуру архива, определить, какие показатели можно визуализировать, сформулировать идею проекта и собрать технический пайплайн
Пайплайн
- Распаковка архива и изучение структуры датасета
- Подсчет MRI-снимков по классам ND, VMD, MD, MoD
- Подсчет распределения по train, valid и test
- Сверка результатов с CSV-файлами классов
- Формулирование главного вывода по датасету
- Выбор графиков для разворота: баланс классов, split-схема, MRI-шкала и матрица
- Проектирование журнального разворота как носителя инфографики
- Подбор MRI-миниатюр по одному примеру на каждый класс
- Сборка SVG-графики
- Создание обложки и трех мокапов, показывающих инфографику как журнальный разворот



