
1 // Описание проекта, идея


Фотографии Наоми (также использованные в датасете)
В период сессии третьего модуля все мы мечтаем об отдыхе — и я не исключение! Но теперь я путешествую не одна, в моей жизни появилось, кажется, одно из самых неугомонных и счастливых существ, моя милая Наоми, миниатюрный восьмимесячный пудель.
В рамках своего проекта я размышляла по поводу того, куда хочу уехать, какие места посетить и с чем познакомить свою любимицу, а после «помещала» её в знаковые места разных стран, моделируя снимки, которые однажды обязательно повторю. Пойдем гулять, Наоми, от Парижа до Рио-де-Жанейро!
Важно, что каждый этап проекта требовал изучения и использования разного ПО: Stable Diffusion (обучение генеративной нейросети);
1 // Google Colab (среда выполнения);
2 // Hugging Face (получение токена для обучения нейросети, дальнейшая загрузка полученной модели на сайт);
3 // Chat GPT (создание сложных элементов кода, консультирование);
4 // Adobe Illustrator (обработка скриншотов кода).
2 // Обучение, работа с кодом

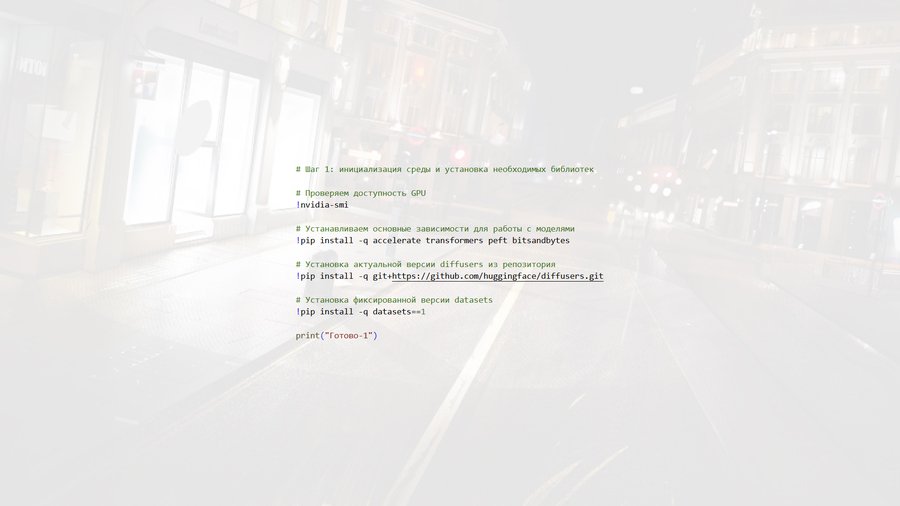
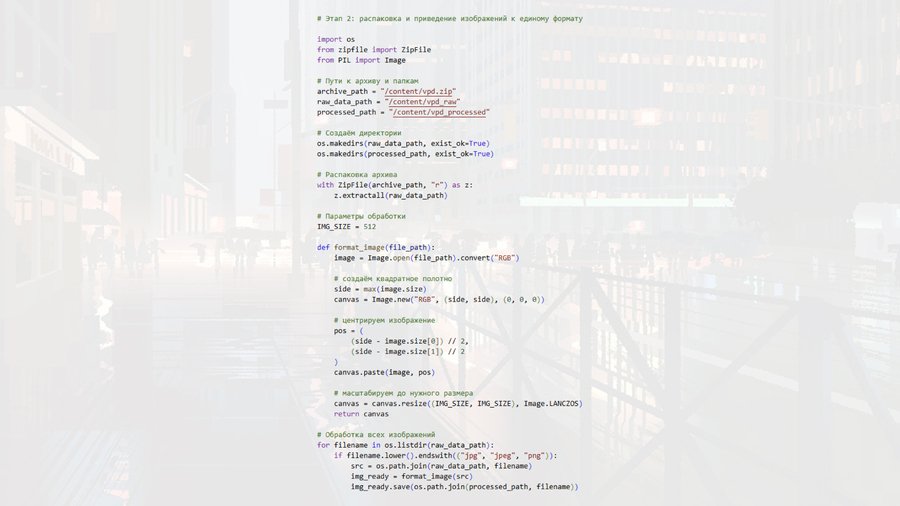

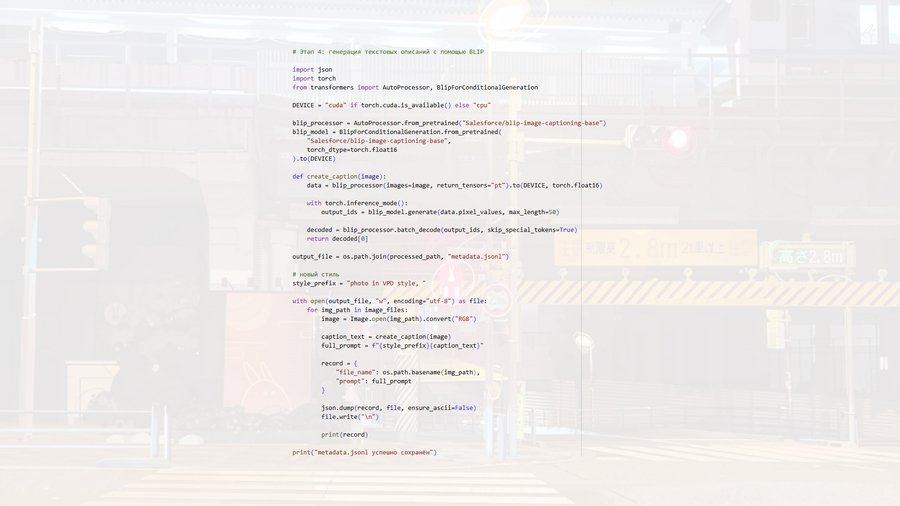




Скриншоты кода (каждый этап подписан!)
В рамках моего проекта код «выстраивает» последовательную систему обработки визуальных данных, в которой каждый этап направлен на подготовку и последующее воспроизведение заданного стиля (изображения моей Наоми).
На начальном этапе осуществляется загрузка изображений из рабочей директории и их базовая организация: файлы приводятся к единому формату, при необходимости изменяется их размер, а структура папок упрощает дальнейшую автоматизированную обработку. Этот шаг формирует исходный датасет, который используется на всех последующих стадиях и определяет качество и характер будущей генерации.
Далее в коде подключается модель BLIP, применяемая для автоматической генерации текстовых описаний изображений. Для каждого файла формируется подпись, отражающая его визуальное содержание, после чего к ней добавляется единый стилевой префикс. Полученные пары «изображение -текст» записываются в файл metadata.jsonl, что позволяет структурировать данные в формате, удобном для обучения. Таким образом формируется текстово-визуальный датасет, где каждое изображение сопровождается описанием, задающим направление интерпретации.
Заключительный этап включает использование подготовленного датасета для обучения модели и последующей генерации изображений. В коде задаются параметры обучения, подключаются необходимые библиотеки и указывается путь к сформированному metadata.jsonl. После завершения обучения модель используется для генерации новых изображений на основе текстовых запросов, в которых учитывается ранее заданный стиль. Итоговые результаты отражают взаимосвязь между исходными данными, автоматически сгенерированными описаниями и параметрами обучения, объединёнными в единую систему.
3 // Результирующая серия изображений


Первым «направлением» стали одни из самых узнаваемых городов (которые мы обязательно посетим с Наоми) — Токио и Париж. Важно, что в промптах для создания этих и последующих изображений я не использовала описания породы, цвета и прочего, заменяя все особенности внешности Наоми лаконичным «dog».
И это работало! Составив датасет исключительно из изображений моего питомца, я добилась того, что общий запрос выдавал конкретное животное (что важно: не саму породу, а именно мою собаку, не случайного щенка и не случайную взрослую особь).
Промпты (здесь и далее: первый промпт для левого изображения, второй для правого):
1 // «photo in VPD style, " (мой префикс) «a dog exploring the streets of Shinjuku, Tokyo,» «Mode Gakuen Cocoon Tower in the background,» «futuristic architecture, dramatic perspective with swirling clouds,» «vibrant city lights, highly detailed and lifelike textures»
2 // «photo in VPD style, " «a dog wandering near the Eiffel Tower in Paris,» «dramatic clouds, cinematic lighting,» «strong perspective, vibrant urban background,» «highly detailed, lifelike textures»


Промпты (Лондон и (опять!) Париж):
1 // «photo in VPD style, a dog walking near Big Ben in London, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog wandering near the Eiffel Tower in Paris, cinematic lighting, detailed textures»


Промпты (Рим и Токио (перекресток Шибуя, для того, чтобы «посещенный» моей виртуальной Наоми город угадывался, я брала классические и узнаваемые достопримечательности):
1 // «photo in VPD style, a dog exploring the Colosseum in Rome, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog exploring Shibuya Crossing in Tokyo, cinematic lighting, detailed textures»


Промпты (Афины и Барселона):
1 // «photo in VPD style, a dog wandering around the Acropolis in Athens, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog near Sagrada Familia in Barcelona, cinematic lighting, detailed textures»


Промпты (Стамбул и Берлин):
1 // «photo in VPD style, a dog walking near Grand Bazaar in Istanbul, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog exploring Brandenburg Gate in Berlin, cinematic lighting, detailed textures»


Промпты (Сидней и Дубай):
1 // «photo in VPD style, a dog wandering around Sydney Opera House, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog near Burj Khalifa in Dubai, cinematic lighting, detailed textures»


Промпты (Рио-де-Жанейро и Нью-Йорк):
1 // «photo in VPD style, a dog near Christ the Redeemer in Rio de Janeiro, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog walking through Times Square, New York, cinematic lighting, detailed textures»


Промпты (вновь Токио (хотя больше похоже на вид с небоскреба в Москва-Сити) и Мачу-Пикчу):
1 // «photo in VPD style, a dog exploring Tokyo Tower, cinematic lighting, detailed textures»
2 // «photo in VPD style, a dog exploring Machu Picchu in Peru, cinematic lighting, detailed textures»
В завершении описания блока с изображениями-результатами я бы хотела поделиться личным переживанием и отношением к итогу проекта: мне нравится то, как изображения, созданные на основе «домашних», «случайных» и не постановочных кадрах, повторяют это расслабленное отношение к фотографии, её бытовой характер. Кажется, если бы я делала их по-настоящему, а не генерировала, то фото вышли бы точно такими же!
Промпт для завершающего изображения (это не мое фото!): «photo in VPD style, a dog near Niagara Falls, cinematic lighting, detailed textures»



